Beheer en monitoring
Concept
Vanwege het stelselkarakter zijn heldere afspraken over het beheer noodzakelijk. Er zijn vaak meerdere partijen bij een wijziging of incident betrokken. In het afsprakenstelsel zijn daarom afspraken opgenomen waaraan partijen moeten voldoen. Omdat in het Afsprakenstelsel meerdere partijen bij beheer betrokken zijn, is het essentieel dat de verschillende partijen gezamenlijk een goed inzicht en overzicht hebben van de status van netwerken, diensten en componenten die bij elkaar het Samen onder Handbereik stelsel vormen. Enerzijds is er hierbij het beheer en de monitoring van het Afsprakenstelsel zelf, anderzijds het functionele en technische beheer en de monitoring binnen het landschap als geheel.
Beheer en monitoring Afsprakenstelsel
Het doel van dit beheer is te zorgen dat het Afsprakenstelsel aan blijft sluiten bij wat nodig is en continue wordt verbeterd. Dit vindt plaats door roadmaps beschikbaar te maken waarin de ontwikkeling van het Afsprakenstelsel gevolgd kan worden. Door mogelijkheden te bieden om wijzigingsverzoeken en verbetervoorstellen in te dienen en te volgen, maar ook issues die ervaren worden. Er wordt nauw aangesloten bij werkwijzen die aansluiten bij de development praktijk en software ontwikkelende organisaties en afdelingen. Daarnaast worden ook traditionelere kanalen geboden (documenten, formulieren, etc). Uitvoering van het beheer vindt plaats door de partijen, vanuit de verschillende rollen, benoemd in hoofdstuk Governance.
Beheer en monitoring binnen het landschap als geheel
Voor dit beheer is onderscheid te maken naar het beheer van stelselvoorzieningen en beheer in de context van het geheel waarbij ook het beheer bij de deelnemers een belangrijke rol speelt.
Stelselvoorzieningen
Het beheer en de monitoring van de stelselvoorzieningen is recht toe en recht aan. Dit wordt uitgevoerd door de partijen die de stelselvoorzieningen leveren en dat conform afspraken en service level agreements (SLA’s). Het is gericht op het functioneren van de stelselvoorzieningen in lijn met deze afspraken, SLA’s en onderliggende functionele en niet-functionele eisen. Organisaties kunnen bij operationele problemen, verstoringen of wijzigingsverzoeken contact opnemen met de beheerpartijen van de stelselvoorzieningen, en voor niet operationele aspecten met de eigenaar/opdrachtgever voor het leveren, beheren en monitoren van de stelselvoorzieningen. Zie de beschrijving van de rollen in het hoofdstuk Governance.
Decentrale voorzieningen
Omdat er sprake is van een federatief landschap betekent dit dat er niet één beheerpartij is (voor een centrale dienst), maar een landschap van beheerpartijen die in het federatieve landschap alle een eigen verantwoordelijkheid hebben. Concreet betekent dit dat bij problemen, verstoringen of wijzigingsverzoeken het kan zijn dat contact opgenomen moet (kunnen) worden met een specifieke partij in het landschap en mogelijk meerdere. Dit levert een aantal uitdagingen op:
- Het moet idealiter eenvoudig mogelijk zijn vast te kunnen stellen waar in het landschap iets mis gaat of waar een wijziging nodig is. Dit is geen sinecure in een loosely coupled landschap met veel partijen.
- Deelnemers moeten bewust zijn dat zij niet alleen hun eigen interne organisatie moeten bedienen, maar ook organisaties binnen het Afsprakenstelsel. Processen en contactpunten moeten daarop ingericht zijn.
- Deelnemers moeten bewust zijn dat zij zelf niet alles kunnen oplossen en afhandelen, maar daarvoor ook andere organisaties moeten kunnen benaderen en daar afhankelijk van kunnen zijn. Ook hier moeten processen op ingericht zijn.
- Deelnemers moeten bewust zijn dat het uitvoeren van wijzigingen of onderhoud op API’s invloed kan hebben op andere Deelnemers, maar ook dat het niet (tijdig) uitvoeren van wijzigingen of onderhoud dat ook kan hebben.
- Voor bepaalde wijzigingen kan een georkestreerde wijziging nodig zijn bij een tal van partijen tegelijkertijd of in een bepaalde volgorde in de tijd.
Interacties
Zoals hiervoor geschetst zijn soms interacties nodig tussen partijen. De ervaring leert dat dit tijdrovend is en belastend voor organisaties. Belangrijk is het aantal interacties tot een minimum te beperken. Dat kan door:
- In de eerste plaats door de afspraken te volgen, denk aan afspraken rond versiebeheer.
- Duidelijke documentatie te publiceren, bijvoorbeeld op API Management DevPortals.
- Test services (API’s) beschikbaar te stellen zodat anderen deze kunnen ‘pollen’ en zelf kunnen vaststellen dat er connectiviteit is, de achterliggende services operationeel zijn en de basis authenticatie en autorisatie services operationeel zijn.
- Optioneel test services (API’s) beschikbaar te stellen waar functioneel kan worden getest, bijvoorbeeld t.a.v. Inzage en Opdracht.
- (Optioneel?) het uitsturen van gebeurtenissen die service health aangeven op frequente basis en waarbij het niet meer ontvangen daarvan een aanwijzing is dat de service mogelijk niet meer (goed) functioneert, beheerorganisaties kunnen deze gebeurtenissen of het plots ontbreken daarvan nagaan en daar geautomatiseerde acties aan koppelen.
- Test services (API’s) beschikbaar te stellen waar ketenvoorzieningen functioneel kunnen worden getest, bijvoorbeeld t.a.v. het publiceren of bevragen van gebeurtenissen, het terug ontvangen van API calls (van test Services), het kunnen valideren van event (CloudEvent/PROV) syntax, etc. Dit in de vorm van een Self Service Test en Validatie voorziening.
- Optioneel een keten-dashboard te publiceren dat alle test services bevraagd en de status daarvan toont in een ketenbeeld.
Monitoring
Monitoring richt zich in eerste instantie op de eigen services en het eigen ICT landschap. In deze context is het echter ook van belang monitoring breder te zien. Voor beheerafdelingen/teams is het van belang een beeld van het functioneren van het landschap te kunnen hebben en zelf validaties te kunnen doen om na te gaan waar zich verstoringen voordoen. Te denken valt het gebruik van een dashboard welke remote (test) services valideert (zie vorige paragraaf) of het gebruik binnen het beheer en monitoring proces van een centraal dashboard.
Technische invulling
Probleemstelling
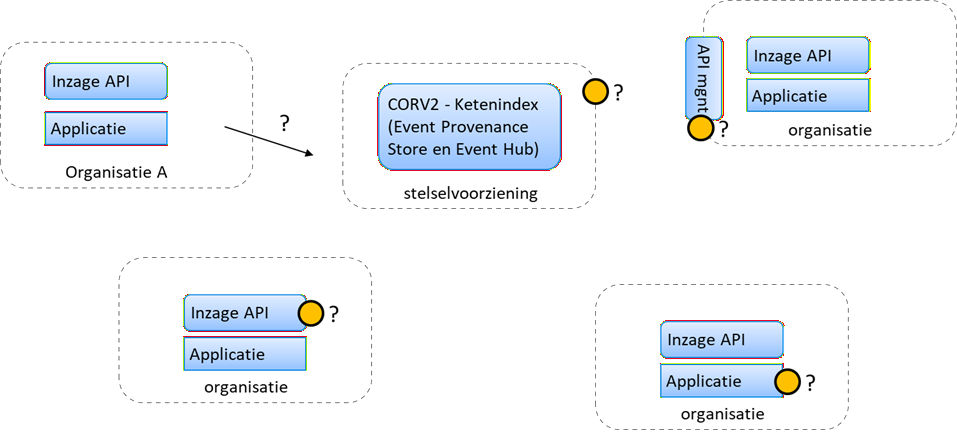
Binnen het estafettemodel, met een centrale dienst (CORV), benaderen alle partijen als er problemen zijn de centrale dienstverlener. Daar is een probleem en de dienstverlener is bezig dat op te lossen, of het probleem is bij een van de aangesloten partijen. De dienstverlener weet welke partij en treedt in contract met die partij. Als het probleem is opgelost wordt het berichtenverkeer automatisch hervat of indien nodig opnieuw aangeboden (door de centrale dienstverlener of op diens aangeven). Bij het netwerkmodel werkt dit anders, hier is ook verkeer tussen partijen direct en zoals de naam netwerkmodel suggereert met een netwerk aan partijen. Als iets niet functioneert is de vraag of dit een stelselvoorziening is (centrale component) of een een probeem bij een van de partijen. De centrale dienstverlener weet dit doorgaans niet en zit ook niet tussen het directe verkeer. Dit is een essentieel verschil. Partijen zullen zelf in staat moeten zijn na te gaan waar zich problemen bevinden en zelf actie moeten nemen die op te (laten) lossen. Zie onderstaande figuur voor een beeld van de situatie. Als er iets niet werkt en de servicedesk van organisatie A gebeld wordt door gebruikers van organisatie A, zal organisatie A na willen gaan wat er aan de hand is. Er kan een probleem zijn met een stelselvoorziening, infrastructuur bij een ketenpartner, een API bij ketenpartner of het achterliggende zaaksysteem/data infrastructuur (waar de API van afhankelijk is). Stel dat het probleem veroorzaakt wordt door een verstoring bij organisatie P en deze organisatie P informatie levert aan enkele tientallen andere organisaties op een reguliere dag, dan wordt die organisatie mogelijk benaderd door tientallen organisaties en min of meer tegelijkertijd. Tot slot is het met veel verschillende partijen een uitdaging te weten hoe je deze partijen kan benaderen via het juiste contactpunt en daarover actuele informatie te hebben.
Oplossing logging en monitoring
Als de API van organisatie P geen antwoord geeft of een 500 terugstuurt, kan dit worden gelogd door zeg organisatie A. Monitoring tooling kan de logging scannen en een melding in de beheertooling doen dat er een verstoring is in het verkeer met organisatie P.
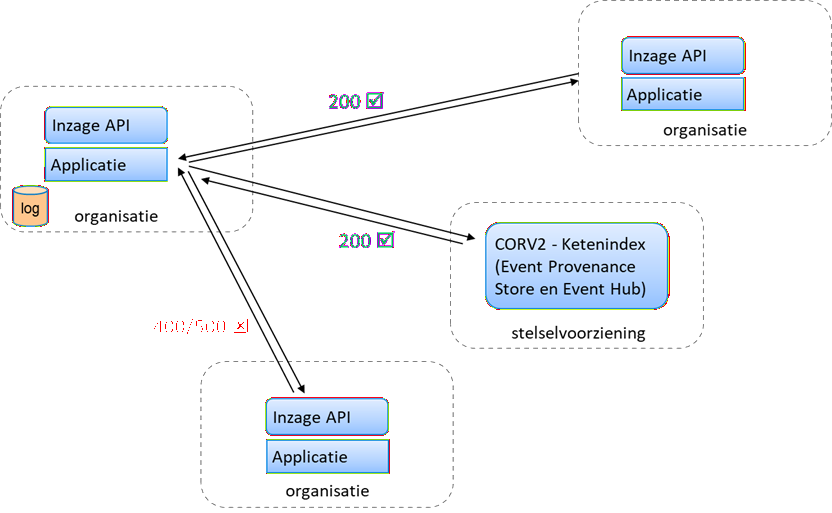
Daar kan proactief geacteerd worden, ook kan het verband worden gelegd als er meldingen binnen op de servicedesk rond informatieschermen (met informatie normaal afkomstig van organisatie P).
Conclusie: Elke partij zal de logging en monitoring moeten inrichten op dit type van monitoring en dat koppelen aan processen (voor opvolging).
Oplossing health check
Voorgaande oplossing werkt maar kan leiden tot veel meldingen en false positives. Een andere oplossing is om te zorgen dat API’s zoals Inzage API’s ook bevraagbaar zijn op health. Zo kan een ‘not healthy’ duiden op niet functioneren van de API of achterliggende systeem en een ‘degraded’ op het niet goed functioneren van de API of achterliggende systeem.
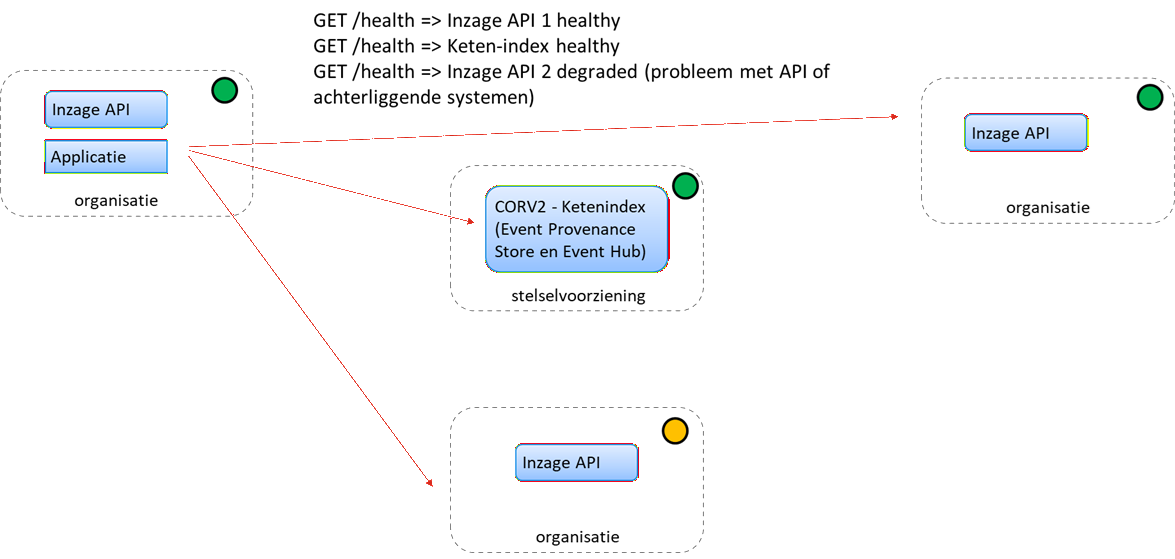
Op zichzelf voegt deze functie weinig toe aan de oplossing hiervoor en vraagt wel een inspanning in het ontwerp en realisatie van de API’s als ook in bevragen daarvan. Deze oplossing is vooral zinvol als deze wordt gecombineerd met centrale of decentrale dashboards. Dergelijke dashboards kunnen een status overview geven en meldingen (push events) sturen van verstoringen of verstoringen bevraagbaar maken (pull).
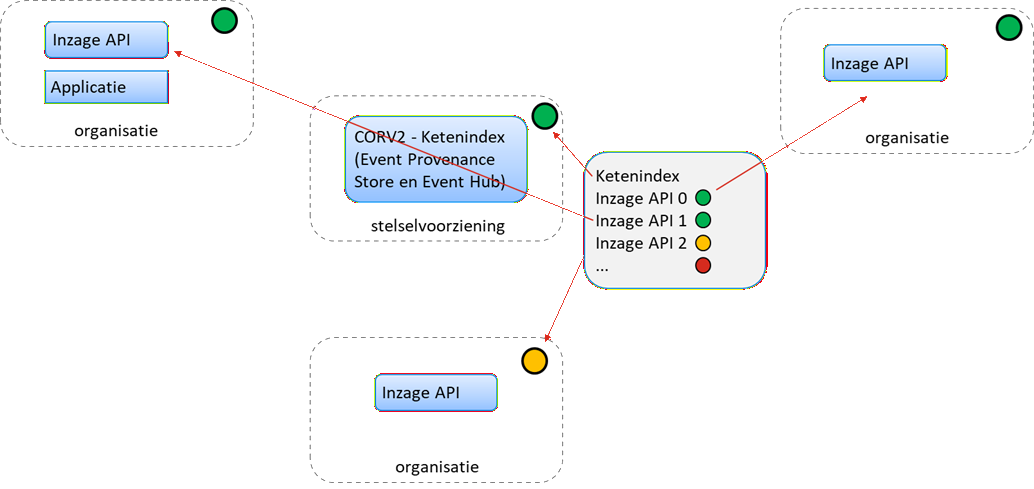
Oplossing melding van verstoring/onderhoud/wijziging
Om minder blind te zijn, waar ook de andere oplossingen zich op richten, is het ook onwenselijk en onnodig veel interacties te hebben tussen beheerpartijen (zie probleembeschrijving). Idealiter is het niet nodig om partijen te bellen, in wachtrijen te vertoeven of e-mail/tickets te sturen, maar kan er eenvoudig worden nagegaan of er onderhoud verstoringen/onderhoud/wijzigingen zijn of zijn geweest door de CORV2 Ketenindex te bevragen waarin organisaties hun verstoringen/onderhoud/wijzigingen hebben gemeld (via events).
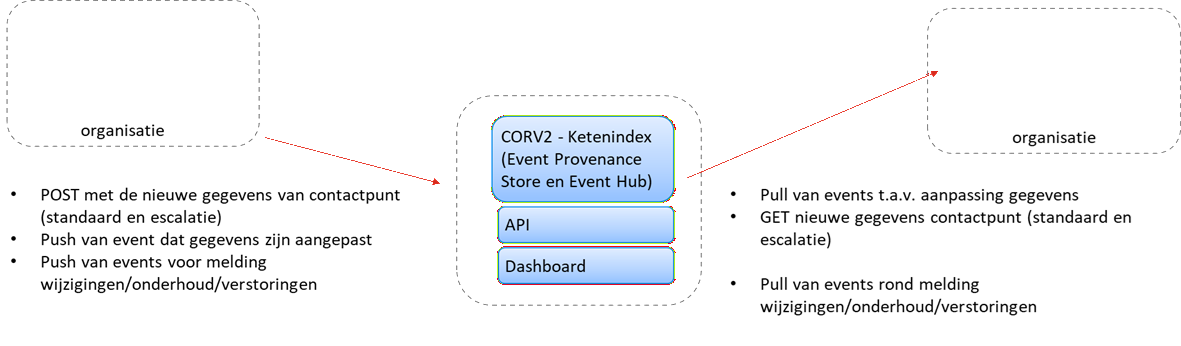
Soms zal een partij dat zelf niet kunnen doen, denk bij een grootschalige uitval, waardoor dit type meldingen ook niet meer werken of gedaan kunnen worden. Door de health polling t.b.v. het centrale dashboard ontstaat echter ook centraal een beeld van dergelijke verstoringen. De centrale health polling zal ook events (van verstoringen) plaatsen in de CORV2 Ketenindex, welke op hun beurt ook opvraagbaar zijn.
Oplossing onderlinge bereikbaarheid
Organisaties melden via events hun contactpunt gegevens, geven wijzingen daarin door (via events). Zodoende is altijd actuele informatie op te halen en kan dat geautomatiseerd. Tevens kan hiermee een actueel centraal overzicht gemaakt worden en dat beschikbaar gemaakt worden via een web-app en via een API (voor geautomatiseerde processen).