Techniek
Definitief
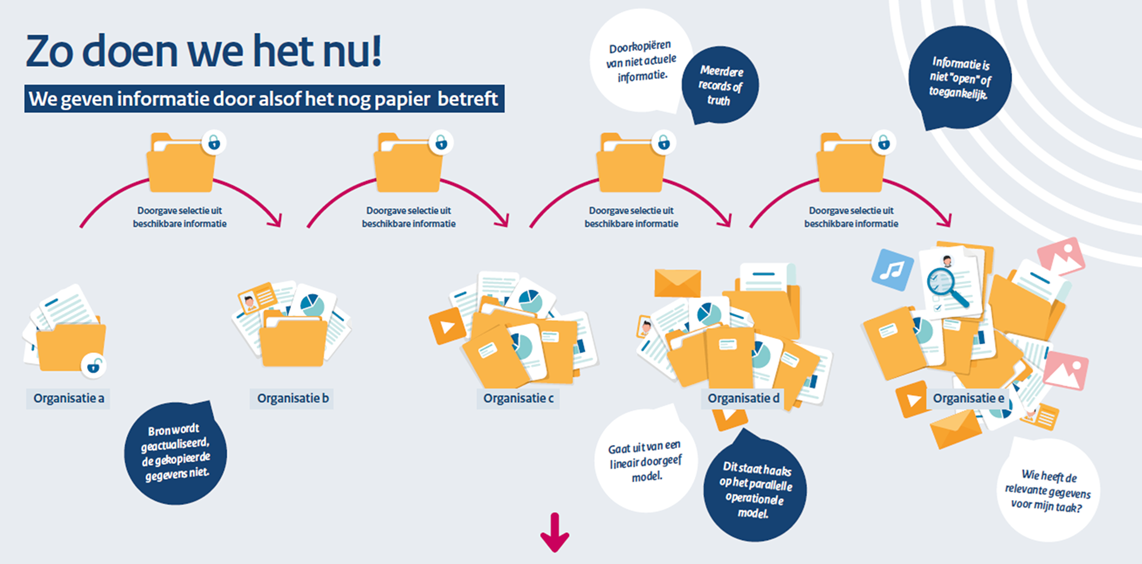
Introductie. Binnen de Jeugd-, Zorg-, en Veiligheidsketens willen we flexibel en transparant digitaal samenwerken. Dat lukt met miljoenen burgers en tussen de honderden partners in het sociaal domein alleen als we dat standaardiseren. Daarvoor ontwikkelden we vijftien standaard samenwerkfuncties, digitale gereedschappen die iedere partner kan opnemen in zijn eigen casussysteem. De huidige digitale infrastructuur CORV, de collectieve opdracht routeervoorziening, moeten we verbeteren om die nieuwe samenwerking te ondersteunen. Samenwerken volgens CORV nú, werkt als een estafette: van een verzender wordt een opdrachtbericht naar een ontvanger gestuurd, die een resultaatbericht terugstuurt. In die berichten zit veel informatie. De ontvanger bewaart en hergebruikt die informatie.
Nadelen van deze manier van samenwerken zijn:
- Andere professionals en burgers hebben geen weet van die opdracht of resultaat en ze hebben geen toegang tot de informatie die erin staat.
- De verzender van een bericht kan de kwaliteit en actualiteit van de kopie niet waarborgen.
- De verzender van een bericht heeft geen controle over het gebruik van zijn informatie.
Deze nadelen gaan we verhelpen in de volgende versie van CORV: CORV 2.0. We breiden CORV uit met twee nieuwe gegevensuitwisselingen: Notificeren en Inzien (aanvullend op de bestaande gegevensuitwisseling Opdracht).
Van:
Naar:
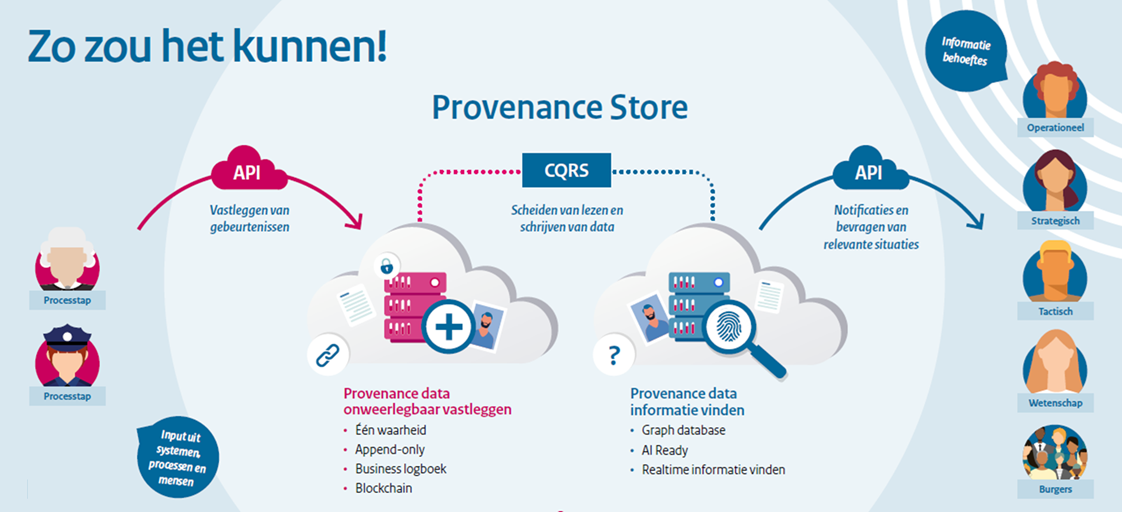
Notificeren wordt gebruikt om andere professionals en burgers te laten weten wat er in de samenwerking gebeurt. De aanbieder van een samenwerkfunctie deelt de gebeurtenissen bij iedere verandering. Een ontvanger kan zich daarop abonneren. Zo’n notificatie is informatie-arm: ze bevatten precies genoeg informatie om te bepalen of ze relevant kunnen zijn voor de ontvanger. De notificaties worden gemaakt volgens de standaard ‘CloudEvents’. De voordelen van zo’n notificatie zijn:
- Doordat je actief wordt geïnformeerd, kun je besluiten te anticiperen op, of parallel te werken met partners.
- Doordat je fijnmazig op de hoogte bent, kun je flexibel reageren in kleine acties.
- Je kunt gericht werken, besluiten wanneer en waarover je contact zoekt en informatie deelt.
Inzien betekent dat een aanbieder gegevensdiensten vanuit zijn bron, zijn casussysteem, aanbiedt. Dit kan zowel spontaan als op basis van een Notificatie worden opgevraagd. Inzien verloopt met behulp van de Digikoppelingstandaard (Digikoppeling Koppelvlakstandaard REST API). De voordelen van Inzien zijn:
- De ketenafhankelijkheid vermindert: je kunt op ieder gewenst moment met actuele informatie werken.
- De transparantie en traceerbaarheid van de overheid neemt toe, doordat ook historische informatie op termijn betrouwbaar beschikbaar is.
- Zo kunnen alle professionals in het eigen casussysteem werken en tegelijk een virtueel “dossier” inzien, opgebouwd door inzage bij bronnen van anderen.
- De burger heeft inzage en kan participeren via een te realiseren burgervoorziening.
- Hiermee ontstaat een betrouwbaar integraal beeld van de kennis in het netwerk voor wie dat nodig heeft.
Dit alles staat of valt natuurlijk met vertrouwen. Daarvoor gaan we in CORV 2.0 de identiteit (wie je bent) en autorisatie (wat je mag) van de afnemer door de aanbieder laten controleren. Daarvoor stappen we naar een schaalbaar, beheerbaar afsprakenstelsel van toegang verlenen op persoonsniveau. We omarmen daarbij de Europese en Nederlandse toegangsstandaards, voor zowel de burger als voor de professional. Voor de burgers bijvoorbeeld DigiD, eHerkenning en de Wallet. Voor professionals de federatieve toegangsoplossingen van het zorg, gemeentelijk en justitieel domein. En we gaan convenanten en doelbinding vertalen in autorisatieregels.
De voordelen van dit zero trust beveiligingsmodel zijn:
- Geautomatiseerde toegangsverlening wordt mogelijk door vooraf afgesproken autorisatieregels
- Toename van privacy: met informatie bij de bron kan de aanbieder fijnmazig, contextueel en adaptief toegang verlenen
- Je krijgt pas toegang tot Opdrachten, Notificaties en Inzage als je identiteit, bevoegdheid en doelbinding digitaal is aangetoond.
CORV 2.0 vraagt een stevige verandering voor partners en pakketleveranciers. Partners moeten via een nieuw ontkoppelpunt, een API-gateway, op CORV 2.0 aansluiten. Op dat ontkoppelpunt zijn de diensten gepubliceerd die je gebruikt, wordt de identiteit en toegang gecontroleerd en de data beschikbaar gesteld. Pakketleveranciers moeten de samenwerkfuncties met Notificaties, Abonnementen en Inzien/Inzage in hun pakket implementeren.
Het vertrekpunt is dat CORV 2.0 federatief en gedecentraliseerd kan werken. Toch voorzien we ook ondersteunende functies in het midden op CORV 2.0. We denken dan aan:
- Een toegangscatalogus met de identiteit van instanties, professionals en centrale autorisatieregels.
- Een dienstencatalogus met een centraal overzicht van beschikbare (data)diensten.
- Een Herkomst en Notificatie register: waarin gebeurtenissen worden gelogd.
- Silvester diensten: tijdelijke diensten die helpen de migratie naar CORV 2.0 te maken.
CORV 2.0 (CORV2) wordt zo een gedistribueerde oplossing van API en gebeurtenissen-voorzieningen. Daarmee maken we weer een belangrijke stap naar netwerksamenwerking onder de vingertoppen.
CORV1
CORV (Collectieve Opdracht Routeer Voorziening) verbindt sinds de decentralisaties rond 2015 de gemeente-, zorg- en justitiewereld om bilateraal berichten te kunnen uitwisselen. Ketenpartners hebben een aansluiting op de CORV via het gemeente-, zorg- of justitienet. Het betreft een centrale dienst in het zogenoemde hub-spoke model. De routeervoorziening is de centrale hub waar de spokes, lees de verschillende organisaties zijn aangesloten. Via CORV worden berichten tussen organisaties uitgewisseld op basis van asynchroon berichtenverkeer (ebMS). CORV maakt gebruik van een push-push patroon. Dat betekent dat berichten van de melder naar CORV worden geduwd, waarbij CORV vervolgens de berichten ook duwt naar de ontvanger. CORV kent verschillende aanvullende services, naast routeren, denk bijvoorbeeld aan vertalen en monitoring.
De CORV-voorziening is gebaseerd op het justitiële service interface (JSI) platform. Dit platform bestaat uit bibliotheken (libraries), componenten, die het realiseren van workflow, translatie en transformatie snel en gestandaardiseerd kunnen. De JSI kent verschillende gestandaardiseerde bouwstenen om service orkestratie, (gegevens)translatie en (protocol)transformatie te realiseren. De JSI-componenten zijn gebaseerd op de programmeertaal Python.
CORV ondersteunt het estafette informatie model goed, maar doet dit vooral op basis van een verouderd protocol (ebMS) en een verouderde methodiek ebMS/WUS berichtenuitwisseling. Die veroudering zorgt (op termijn) voor beperkte ondersteuning door leveranciers, minder makkelijk aan te trekken talent dat kennis heeft van deze techniek, beperkte ondersteuning voor nieuwe wensen en benodigdheden zoals netwerkmodel ondersteuning en ondersteuning van gebeurtenisgedrevenheid.
Vandaar dat CORV2 ontwikkeld wordt. CORV2 ondersteunt zowel het estafettemodel als het netwerkmodel, zowel ebMS als REST API, zowel berichten als vraag-antwoord (REST API) als gebeurtenissen (events). CORV2 zal op termijn geen ebMS/WUS meer ondersteunen. Die termijn zal naar verwachting echter minimaal een decennium zijn. Vandaar dat CORV2 ook een overbruggingsdienst zal bevatten of deze naast CORV2 gepositioneerd zijn. Deze overbruggingsdienst is ook wel bekend onder de naam ‘Silvester’. Deze dienst zal berichten conform estafette model kunnen omzetten naar berichten/events conform netwerkmodel en vice versa. Dus ebMS-berichten kunnen omzetten naar REST API-berichten of events en andersom.
Via het afsprakenstelsel wordt invulling gegeven aan het netwerkmodel. CORV2 is daarbij een, zei het essentieel, hulpmiddel.
Overwegingen CORV2
CQRS
CQRS (Command Query Responsibility Segregation) is een architecturaal patroon dat lees- en schrijfoperaties in een systeem scheidt. Het belangrijkste principe is dat methoden die de status van een systeem wijzigen (commands en events) gescheiden worden van methoden die data opvragen (queries).
CQRS is een belangrijke stap in event-gedreven oplossingen om verschillende redenen:
- Het verbetert de schaalbaarheid door lees- en schrijfworkloads onafhankelijk te kunnen schalen.
- Het maakt optimalisatie mogelijk van datamodellen voor specifieke use cases, met aparte schema’s voor lezen en schrijven.
- Het vereenvoudigt de integratie met event sourcing, waarbij alle statuswijzigingen als events worden opgeslagen.
- Het ondersteunt betere prestaties en flexibiliteit in complexe domeinen door gespecialiseerde lees- en schrijfmodellen te gebruiken.
- Het verbetert de beveiliging door de toegang tot schrijfoperaties beter te kunnen controleren.
Als een dergelijke CQRS-data bron wordt opgenomen in bijvoorbeeld een NoSQL oplossing als graph ontstaan er meerdere voordelen:
- Verbeterde zoekbaarheid: Gegevens zijn eenvoudiger te vinden door geoptimaliseerde opslag en indexering.
- Flexibele datarelaties: Alternatieve dataformaten zoals NoSQL en graph databases maken het leggen en bevragen van complexe relaties tussen gegevens eenvoudiger.
- Snellere query-uitvoering: Geoptimaliseerde indexering zorgt voor efficiënte zoekopdrachten, inclusief mogelijkheden voor full-text zoeken, fuzzy search en geavanceerde zoekfuncties.
- Kunstmatige intelligentie en machine learning: AI en machine learning kunnen patronen en relaties in grote datasets ontdekken, voorspellingen doen over systeemuitval of prestatieknelpunten, en data-gedreven beslissingen ondersteunen.
- Efficiëntere analyse: Het gebruik van flexibele dataformaten vergemakkelijkt het analyseren en verbinden van gegevens, waardoor diepgaandere inzichten mogelijk zijn.
Ontkoppeling via REST API, ook voor events
Gebruik van een API layer / API Proxy ontkoppelt en voorkomt het implementeren van business logica op een centrale plek (dus in CORV2). Het is een generieke best practice geen business logica op een centrale plek te realiseren binnen een federatieve omgeving. Door een REST API-koppelvlak te implementeren, creëren organisaties een uniforme interface voor het lezen en schrijven van events. Dit bevordert de consistentie in dataverwerking en vereenvoudigt de integratie met diverse systemen en applicaties. Het API-koppelvlak fungeert als een abstractielaag, waardoor onderliggende complexiteiten van event storage en retrieval worden verborgen voor de consumenten van de API. Veelal gaan we uit van een request-/ response REST API-koppelvlak. Een API kan ook een event koppelvlak bezitten. REST API’s kunnen geïntegreerd zijn in Event Brokers. REST API’s kunnen zich registeren op webhooks (bijvoorbeeld door WebSub toe te passen) om asynchrone notificaties te ontvangen, zodat een polling mechanisme niet nodig is.
Graph database
Wanneer een graph database wordt gebruikt als event store, ontstaan er enkele unieke voordelen:
- Rijke relaties: Graph databases kunnen complexe relaties tussen events en entiteiten efficiënt modelleren en bevragen.
- Flexibele queries: Het maakt geavanceerde traversals en patroonherkenning mogelijk tussen gerelateerde events.
- Schaalbaarheid: Graph databases presteren goed bij het verwerken van grote hoeveelheden onderling verbonden data.
- Contextbehoud: De graph-structuur helpt bij het behouden van de context rond events.
CORV2 is daarom gebaat bij de toepassing van graph database als event store.
Data lineage / Data provenance
Data lineage of data provenance is het vastleggen van de volledige levenscyclus van gegevens, van hun oorsprong tot hun huidige staat, en het is belangrijk om verschillende redenen. Ten eerste helpt het bij het verifiëren van de datakwaliteit en betrouwbaarheid door een duidelijke geschiedenis van transformaties te bieden. Daarnaast maakt het de dataverwerking transparant en houdt het gegevensverwerkers verantwoordelijk voor hun acties, wat bijdraagt aan de integriteit van gegevens.
Bovendien ondersteunt data lineage organisaties bij het voldoen aan wettelijke en industriële standaarden door de nauwkeurigheid en legitimiteit van gegevens te waarborgen. Het stelt ontwikkelaars en data-analisten ook in staat om de oorsprong en transformatie van gegevens te traceren, waardoor fouten efficiënt kunnen worden opgespoord en gecorrigeerd. Dit proces helpt verder bij het opbouwen van vertrouwen in de gegevens door de herkomst en authenticiteit ervan te bevestigen. Tot slot bevordert data lineage de reproduceerbaarheid van onderzoeksresultaten door een gedetailleerde trail van gegevensbewerkingen te bieden. Hierdoor kunnen organisaties de integriteit van hun gegevens waarborgen, besluitvorming ondersteunen en voldoen aan steeds strengere eisen op het gebied van gegevensbeheer en privacy.
Event stores passen goed bij data lineage of data provenance om verschillende redenen:
- Chronologische vastlegging: Event stores leggen gebeurtenissen chronologisch vast, wat perfect aansluit bij het traceren van de herkomst en transformatie van data over tijd.
- Onveranderlijke geschiedenis: Events worden opgeslagen in een onveranderlijk formaat, waardoor een betrouwbare en volledige historische weergave van alle datawijzigingen behouden blijft.
- Gedetailleerde tracking: Elke datawijziging wordt als een afzonderlijk event opgeslagen, wat een zeer gedetailleerd inzicht geeft in hoe data is getransformeerd en verplaatst.
- Reconstructie van toestanden: Door events sequentieel af te spelen, kan de toestand van data op elk willekeurig moment in de geschiedenis worden gereconstrueerd.
- Foutcorrectie en audittrail: Event stores bieden mechanismen voor foutcorrectie zonder de originele events te wijzigen, wat cruciaal is voor nauwkeurige data lineage.
- Flexibiliteit in analyse: De eventgebaseerde structuur maakt het gemakkelijk om complexe queries uit te voeren en datastromen te analyseren, wat essentieel is voor data provenance.
Event Datamodel
Het is essentieel dat er een gestandaardiseerd keten Event Datamodel toegepast wordt en dat model wordt beheerd. Standaardisatie van het event datamodel biedt verschillende voordelen voor organisaties die event sourcing toepassen.
Ten eerste zorgt een gestandaardiseerd event datamodel voor consistentie en interoperabiliteit binnen en tussen systemen. Dit maakt het gemakkelijker om events uit te wisselen, te verwerken en te interpreteren, ongeacht waar ze zijn gegenereerd of worden gebruikt. Standaardisatie bevordert ook de schaalbaarheid en flexibiliteit van event-gebaseerde systemen, omdat nieuwe componenten of diensten eenvoudiger kunnen worden geïntegreerd wanneer ze een gemeenschappelijk datamodel volgen.
Daarnaast is het juiste beheer van het event datamodel cruciaal voor de langetermijnwaarde en bruikbaarheid van de opgeslagen events. Events zijn immers de onveranderlijke feiten die de basis vormen van het systeem. Een goed beheerd datamodel zorgt ervoor dat events begrijpelijk en bruikbaar blijven, zelfs als de systemen en processen eromheen evolueren. Dit is vooral belangrijk omdat events vaak worden gebruikt om de volledige geschiedenis van een systeem te reconstrueren of om complexe analyses uit te voeren.
Het beheer van het event datamodel moet rekening houden met de dynamische aard van bedrijfsprocessen en datarelaties. Entiteiten en hun relaties kunnen veranderen over tijd, en het datamodel moet flexibel genoeg zijn om deze veranderingen te accommoderen zonder de integriteit van historische data te compromitteren. Dit vereist een zorgvuldige aanpak van datamanagement, waarbij veranderingen in het model worden gedocumenteerd en backward compatibility wordt gewaarborgd.
Door een gestandaardiseerd en goed beheerd event datamodel te hanteren, kunnen organisaties de volle potentie van event sourcing benutten. Het stelt hen in staat om betrouwbare audit-trails te maintainen, complexe analyses uit te voeren, en systemen te bouwen die robuust en aanpasbaar zijn aan veranderende zakelijke behoeften.
Gebeurtenissen (events)
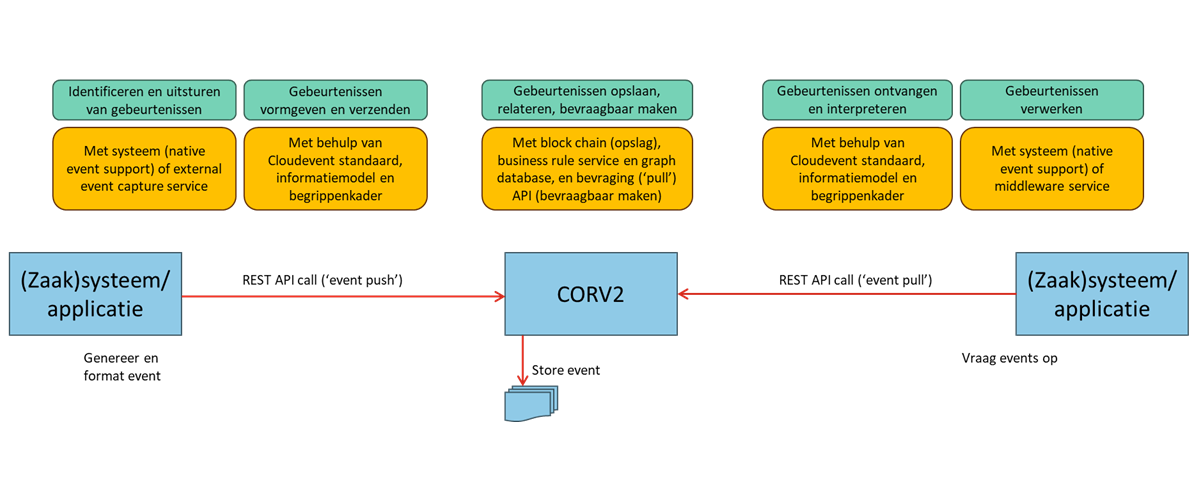
Identificeren en uitsturen van gebeurtenissen
Binnen het stelsel willen we gebeurtenissen kunnen delen. Bijvoorbeeld: “Wij Politie hebben zojuist melding xyz gedaan bij Veilig Thuis”. Een eerste vraag is dan hoe we gebeurtenissen kunnen identificeren en uitsturen vanuit de bron, lees het systeem dat de desbetreffende partij gebruikt. Hier zijn grosso modo de volgende mogelijke manieren voor:
- Het (business/zaak)systeem ondersteunt native het genereren en uitsturen van events.
- Het (business/zaak)systeem ondersteunt eventcreatie en verzending nog niet, maar dit kan in het systeem worden ingebouwd.
- Het (business/zaak)systeem ondersteunt eventcreatie en verzending niet, maar met ‘External Event Capture’ functionaliteit kunnen alsnog events worden gegenereerd en uitgestuurd.
Denk bij dit laatste aan het monitoren van applicatie logging (log scraping), database triggers/capture (CDC) of automation hooks (RPA of automation tool). Zodoende kunnen events worden geïdentificeerd, geëxporteerd, onderschept of gesynthetiseerd en vervolgens worden uitgestuurd.
Gebeurtenissen vormgeven en verzenden
Een gebeurtenis wordt vormgeven binnen de CloudEvents standaard en conform het NL GOV profile for CloudEvents. De daadwerkelijke inhoud is afgeleid van het betreffende informatiemodel van de betreffende samenwerkfunctie (zie Samenwerkfuncties). Objecten en attributen volgen waar afgesproken de definities van het Begrippenkader.
De gebeurtenis wordt verzonden naar de CORV2 event broker. Deze biedt hiervoor een REST API aan (REST API Proxy naar Event Platform event-log/topic). De REST API wordt aangeroepen en het event via deze API aangeleverd. De REST API is beschreven in het API Management DevPortal van CORV2.
Gebeurtenissen ontvangen en interpreteren
De organisatie welke gebeurtenissen wil (of moet) ontvangen kan via de betreffende REST API (REST API Proxy naar Event Platform event-log/topic) een ‘pull’ actie uitvoeren en zodoende (relevante) gebeurtenissen ophalen.
Uiteraard is toegang nodig tot deze REST API en de gebeurtenissen. Wat betreft gebeurtenissen zijn hier twee varianten:
- De betreffende gebeurtenissen zijn voor de gehele keten toegankelijk. Merk op dat de gebeurtenis (het event) weinig informatie bevat en er een inzage verzoek nodig is voor meer informatie.
- De betreffende gebeurtenissen zijn alleen toegankelijk voor partijen die een toegangsverzoek hebben gedaan, dat is gehonoreerd. Zij ontvangen dan een token waarmee de gebeurtenissen toegankelijk worden. Ook hier zal doorgaans een inzage verzoek nodig zijn voor meer informatie.
Het genoemde inzage verzoek kent een eigen toegangsverleningsproces (authenticatie/autorisatie).
Interpretatie van gebeurtenissen wordt gefaciliteerd door enerzijds de CloudEvent standaard. De REST API-response bevat de in de CloudEvents standaard en conform het NL GOV profile for CloudEvents vormgegeven event. Anderzijds door event informatiemodel. Dit gaat over wat in het Cloud Event wordt geplaatst (welke attributen/headers). Dit is ook wel bekend onder de noemer Schema registry pattern. Een Schema registry levert versioning en backward and forward compatibility. Verder wordt de interpretatie gefaciliteerd door het informatiemodel en daarmee ook door de definitie van objecten en attributen conform het keten Begrippenkader en door de samenwerkfunctie (zie Samenwerkfuncties).
Gebeurtenissen verwerken
Ontvangen en (kunnen) interpreteren is niet voldoende. Gebeurtenissen moeten kunnen worden verwerkt in het (business/zaak)systeem. Hier zijn grosso modo de volgende mogelijke manieren voor:
- Het (business/zaak)systeem ondersteunt native events subscription en verwerking. Het systeem kan de events verwerken, ‘parsen’ en acties nemen op basis van de inhoud van de events.
- Het (business/zaak)systeem ondersteunt events subscription en verwerking nog niet, maar dit kan in het systeem worden ingebouwd.
- Het (business/zaak)systeem ondersteunt eventcreatie en verzending niet, maar met ‘middleware services’ kunnen de events alsnog worden verwerkt en acties uitgezet worden, bijvoorbeeld door transformatie naar systeem-API calls, system calls, database mutaties of UI automation acties.
Onderdeel van de verwerking van gebeurtenissen is het analyseren daarvan via bijvoorbeeld business rules of workflow engines. Op basis van de analyse kunnen acties worden uitgezet (binnen het systeem / de applicatie). Dit kan binnen de applicatie zelf of binnen daarvoor bestemde (middleware) services.
Gebeurtenissen routeren
Binnen het stelsel moeten gebeurtenissen tussen verschillende organisaties uitgewisseld kunnen worden. Technisch bezien zou dat direct kunnen, dus zonder centrale of gedeelde voorzieningen. In praktische zin echter niet, gelet onder andere de complexiteit en schaalbaarheid. Er is voor de uitwisseling van gebeurtenissen dus een gedeelde voorziening nodig (CORV2).
De uitwisseling en routering van de gebeurtenissen kan in een publish/subscribe (pub/sub) model. Doorgaans wordt hiervoor gekozen wanneer sprake is van gelijksoortige omgevingen en daardoor ook native pub/sub interfaces gebruikt kunnen worden, of wanneer het aantal organisaties waarmee wordt uitgewisseld beperkt is. In dit geval is van geen van beide sprake. Vandaar dat gekozen wordt voor een benadering die in een hogere mate loosely coupled is dan pub/sub. Die benadering maakt gebruik van REST API interfaces die voor de logg/stream/topic interfaces geplaatst worden en van het push/pull model (in plaats van pub/sub). Organisaties (event producers) sturen gebeurtenissen via een gedefinieerde standaard REST API naar de Event Hub (CORV2), ontvangende organisaties (consumers) bevragen (pull) de Event Hub op nieuwe berichten.
Gebruik van de CloudEvent standaard
CloudEvents is een open standaard voor het gestandaardiseerd beschrijven van gebeurtenisgegevens, zodat verschillende diensten en platforms eenvoudig events kunnen uitwisselen; de standaard is techniek-neutraal en definieert alleen de context metadata, niet de inhoud van de payload. De standaard beoogde interoperabiliteit en consistente event-uitwisseling in event-driven systemen te bevorderen. De standaard volgt de volgende ontwerpprincipes: minimaal, uitbreidbaar, format- en transportonafhankelijk, en modulair (core-specificatie plus bindings voor protocollen).
Belangrijkste elementen van een CloudEvent:
| specversion | De versie van de CloudEvents specificatie die gebruikt wordt. |
| — | — |
| id | Een unieke identifier voor het event. |
| source | De bron die het event genereert (URI of identifier). |
| type | Het type gebeurtenis, vaak een naam die aangeeft wat er gebeurde. |
| time | Optioneel tijdstip waarop het event is gegenereerd. |
| subject | Optioneel onderwerp dat het object identificeert waarop het event betrekking heeft. |
| datacontenttype | Geeft het media-type van de data aan, bijvoorbeeld application/json. |
| data | De event-payload zelf; inhoud en structuur bepaald door producent en consument. |
| dataschema | Optioneel URI naar een schema dat de structuur van data beschrijft. |
| extensions | Extra, optionele sleutel/waarde-attributen om de basisset uit te breiden voor specifieke domeinen of implementaties. |
Alle hierboven genoemde contextattributen vormen de minimale metadataset die CloudEvents definieert.
CloudEvents definieert geen enkel transportprotocol; er bestaan officiële bindings voor veelgebruikte protocollen zoals HTTP, AMQP, Kafka en MQTT. Deze bindings beschrijven hoe de CloudEvent velden worden gemapt naar headers, velden of berichtvormen binnen het gekozen transport. Er bestaan twee belangrijke serialisatiemodi: structured (metadata en data verpakt in één bericht body) en binary (metadata in headers, data in body).
De standaard staat expliciet toe dat extra attributen toegevoegd mogen worden; die worden “extensions” genoemd. Extensions vallen binnen de standaard, zolang ze de regels volgen die in de CloudEvents specificatie voor contextattributen, serialisatie en bindings zijn vastgelegd.
Voorbeelden van extensions zijn:
| Correlation-id | Correlatie-id’s of vergelijkbare correlatievelden voor samenhang tussen gerelateerde events voor audit en foutafhandeling en observeerbaarheid binnen de keten. |
| — | — |
| distributed tracing/traceparent | Tracing context (trace-id, span-id), tracing headers voor end‑to‑end ketenmonitoring. |
| Dataref | Verwijzing naar payload die extern opgeslagen is. |
| Severity | Prioriteits- of ernstniveau van het event. |
| expirytime / deprecation / recordedtime | Aanvullende tijdstempels of levensduurinformatie. |
Een correlation-id is een eenvoudige, vaak application level unieke identifier die bedoeld is om alle logregels, events of berichten die bij één higher‑level request horen te koppelen.
Distributed tracing is een methode om één verzoek of transactie te volgen, terwijl het door meerdere services, processen of systemen loopt. Het splitst de volledige keten in kleinere eenheden, genaamd ‘spans’. Elke span representeert een specifieke operatie en bevat timing, status en relationele informatie. Een set van gerelateerde spans vormen samen een trace die het volledige verhaal van de oorspronkelijke actie vertelt.
Traceparent is een gestandaardiseerd header veld (definieert door de W3C Trace Context specificatie) dat de minimale trace context transporteert tussen services. De waarde bevat doorgaans:
- een versieveld,
- een Trace ID (unieke ID voor de volledige trace),
- een Parent/Span ID (unieke ID voor de huidige span of het directe ouderobject),
- traceflags (bijv. sampling bits die aangeven of deze trace moet worden opgeslagen).
Traceparent wordt meestal in HTTP‑headers of vergelijkbare transportheaders meegestuurd zodat elke service de context kan lezen, een nieuwe span kan openen (met eigen span-id) en de context door kan geven naar downstream calls. Traceheaders, zoals traceparent, vallen buiten de ce prefix en volgen de W3C Trace Context-standaarden; ze mogen naast CloudEvent headers bestaan.
Er kan sprake zijn van community-gedefinieerde extensions. Er is een plek waar voorgestelde extensions worden besproken en gedocumenteerd, zodat meerdere implementaties ermee interopereren. Er kan ook sprake zijn van proprietary extensions. Organisaties kunnen eigen extensions gebruiken, maar interoperabiliteit vraagt openbare documentatie of registratie.
CloudEvents biedt twee belangrijkste content modes: Binary en Structured.
In Binary mode worden de event-data in de HTTP-body geplaatst, terwijl de event-attributen als HTTP-headers worden toegevoegd. Dit is efficiënt en makkelijk te verwerken door systemen die alleen de data willen gebruiken; metadata kan genegeerd worden. De CloudEvents-headers krijgen het voorvoegsel ce-, bijvoorbeeld ce-type en ce-id .
In Structured mode worden zowel de event-data als attributen samengevoegd in één gestructureerd payload, meestal als een JSON-object. Dit maakt het mogelijk om het event als geheel eenvoudig door te geven tussen systemen en protocollen, omdat alles in het bericht zit. De complete CloudEvent wordt als één entiteit verstuurd, zonder aparte headers voor de attributen.
CloudEvent standaard NL GOV profile
Het NL GOV profile is een set Nederlandse afspraken boven op de internationale CloudEvents‑standaard die specifiek richting geeft voor gebruik binnen de Nederlandse (semi‑)publieke sector; het profile richt zich primair op notificaties en wil interoperabiliteit, samenhang en dataminimalisatie bevorderen. Het profile beperkt en concretiseert het gebruik van CloudEvents voor notificatie‑scenario’s binnen de overheid en definieert een functioneel toepassingsgebied voor die notificaties. Het profile is bedoeld om samenwerking tussen overheidsorganisaties te vereenvoudigen en informatie tijdig en efficiënt uit te wisselen.
Het NL GOV profile voegt aan de standaard het volgende toe:
- Verplichte toepassing voor notificaties: het profile richt zich op notificaties als beoogde toepassing en bevat afspraken die implementaties voor dit gebruik stroomlijnen.
- Nationale afspraken over metadata en semantiek: het profile legt nadere conventies vast voor context‑attributen, naamconventies en het gebruik van types/sources, zodat producenten en consumenten dezelfde semantiek delen.
- Aanbevelingen voor dataschema’s en documentatie: het profile benadrukt dat dataschema’s en duidelijke documentatie bij events horen, zodat ontvangers payloads betrouwbaar kunnen verwerken.
- Bindingen en implementatiepraktijk: het profile geeft richting aan welke transportbindings en serialisatiemodi in Nederlandse implementaties praktisch wenselijk zijn en hoe die gebruikt moeten worden.
- Governance en beheer: Logius verzorgt beheer en publicatie van het profile en het proces rond onderhouden en consulteren van de standaard, inclusief consultaties en toetsing voor opname op de “pas‑toe‑of‑leg‑uit‑lijst”.
Meer concreet vereist het NL GOV profile:
- Aanvullende regels rond elementen, zoals t.a.v. “source”: “SHOULD be a URN notation with ‘nld’ as namespace identifier”.
- Er zijn twee CloudEvents extension attributes (‘dataref’ and ‘sequence’) toegevoegd als optionele attrbuten in het NL GOV profile, omdat de verwachting is dat deze vaak nodig zullen zijn.
- Er zijn aanvullende algemene gebruiksregels toegevoegd, zoals rond het onderwerp security: “Sensitive information SHOULD NOT be carried or represented in context attributes.” En “Domain specific event data SHOULD be encrypted to restrict visibility to trusted parties.”, maar ook ten aanzien van algemene praktische afspraken, zoals “Consumers SHOULD accept events of a size of at least 64 KByte.” (Dit zijn slechts enkele voorbeelden, zie het NL GOV profile voor alle vereisten.)
Het NL GOV profile legt geen dwingende keuze op tussen Binary en Structured mode. Beide moeten ondersteund kunnen worden.
Zie de CloudEvents-documentatie.
Bevragingen en opdrachten (REST API)
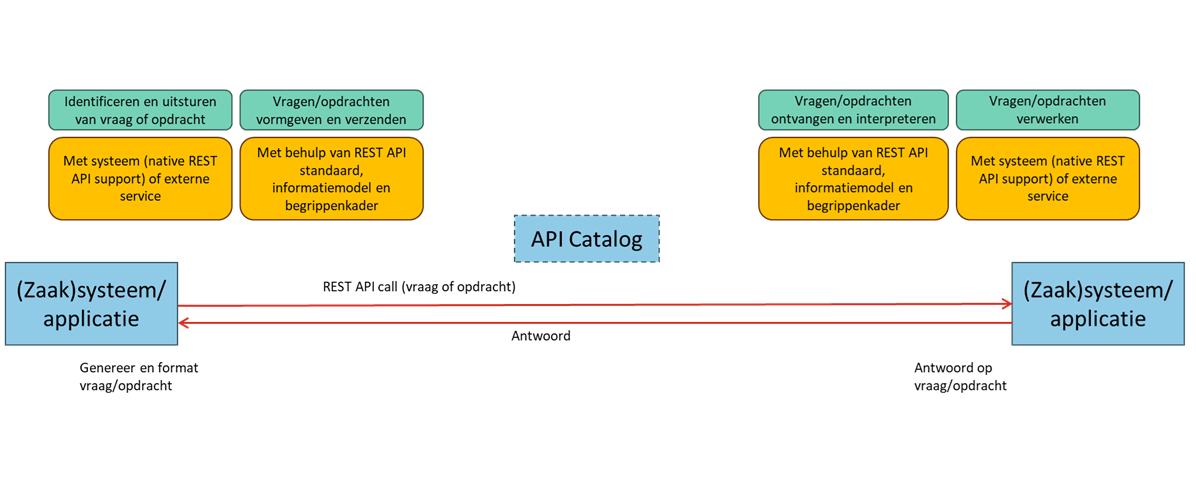
Identificeren en uitsturen van vraag of opdracht
Binnen het stelsel moet informatie opgevraagd kunnen worden of opdrachten uitgezet. Ook kan sprake zijn dat informatie moet worden gewijzigd of verwijderd. Meer technisch geformuleerd zouden we kunnen spreken over CRUD. CRUD staat voor Create, Read, Update en Delete. REST API’s zijn zeer geschikt voor dit type operaties. Op basis van het Keteninformatiemodel, het Begrippenmodel en de Samenwerkingsfuncties en Samenwerkpatronen kunnen vragen of opdrachten worden samengesteld in de vorm van REST API calls.
Als reeds bekend is welke REST API we nodig hebben kan deze worden aangeroepen. Als dit nog niet het geval is kan deze worden opgezocht door de API-Catalog te raadplegen.
De REST API’s calls kunnen direct vanuit het (zaak)systeem/applicatie worden gedaan of kunnen specifieke (micro)services worden ingezet.
Vragen/opdrachten vormgeven en verzenden
Aanbieders van de REST -API publiceren deze in hun API DevPortal. Daar is in meer detail na te gaan hoe de API calls vormgegeven dienen te worden, hoe toegang kan worden aangevraagd etc. Verder helpen het Keteninformatiemodel, het Begrippenmodel en de Samenwerkingsfuncties en Samenwerkpatronen bij de vormgeving van de calls. Andersom helpen deze ook hoe de REST API’s door de aanbieder ervan gebouwd en aangeboden dienen te worden.
Vragen/opdrachten ontvangen en interpreteren
Een REST API kent een synchroon karakter. Op een call volgt direct een antwoord. Ook hier helpen het Keteninformatiemodel, het Begrippenmodel en de Samenwerkingsfuncties en Samenwerkpatronen bij de interpretatie van het antwoord.
Vragen/opdrachten verwerken
De verwerking van de ontvangen response vindt plaats in het (zaak)systeem/applicatie of daaraan gerelateerde specifieke (micro)services.
Typen REST API’s
Enerzijds zullen er resources-API’s zijn. Deze volgen de interne / domeinspecifieke resources met overeenkomstige duidelijke, consistente, zelfstandige naamwoorden (nouns) conform de API-Design Rules. Deze zullen doorgaans worden geabstraheerd achter wat we keten-API’s noemen. Die volgen het afgesproken Keteninformatiemodel en het Begrippenkader en daarmee niet noodzakelijkerwijs de achterliggende resource benamingen (binnen het systeem/applicatie en het informatiemodel daarvan). Deze keten-API’s kunnen meerdere achterliggende resources-API’s benaderen om bijvoorbeeld het aantal API call’s te reduceren. De keten-API’s kunnen ook achterliggende business-API’s benaderen. Een business-API richt zich op bredere bedrijfsprocessen of business-capabilities als resource. In plaats van data-objecten op een lager niveau richt een business-API zich op functionele eenheden die een businessdoel dienen. Dat in tegenstelling tot een resource-API welke is gebouwd rondom het concept van resources en daarmee van data entiteiten of objecten die via unieke URI’s worden geïdentificeerd.
Wijzigingen in API’s
Wanneer zoals in deze context sprake is van een groot aantal partijen zal in de regel ook sprake zijn van een relatief groot aantal wijzigingen in REST API’s. Bovendien zal het onvoorspelbaar zijn wie wanneer welke wijziging zal doorvoeren. Als een organisatie bij veel andere partijen bevragingen doet, kan dit voor die organisatie potentieel een aanzienlijk probleem vormen. Namelijk om zich aan te passen op al de wijzigingen, maar ook om problemen als gevolg van ‘breaking changes’ veroorzaakt door die partijen op te lossen. Om de gevolgen hiervan te mitigeren zijn er twee maatregelen:
- Het volgen van de OpenAPI Specification (OAS) en REST API-Design Rules verplichtingen en adviezen t.a.v. wijzigingen, versionering, versie nummering, documentatie, succes/failure feedback, etc.
- Het hanteren van Afsprakenstelsel op zichzelf waar vooral de standaardisatie van de samenwerkfunctie API’s het genoemde probleem in aanzienlijke mate beter beheersbaar maakt.
Tijdreizen in bevragingen
Het kan nodig zijn om te kunnen tijdreizen binnen het stelsel. Dat wil zeggen dat bijvoorbeeld een inzage die heeft plaatsgevonden, later in de tijd opnieuw kan worden gedaan met dezelfde uitkomst, of dat (onweerlegbaar) is na te gaan wat die inzage destijds als response terug heeft gegeven. Er zijn verschillende manieren om dit in te kunnen vullen, denk aan:
- De backend kan versiegeschiedenis of een historietabel bijhouden. Zo kan bijvoorbeeld bij elke update een snapshot of delta in een historieopslag worden gezet. Dit is vooral relevant als het doel is om dataveranderingen te historiseren, niet alleen de API-calls zelf.
- Het vastleggen van elke API-aanroep in een logbestand of auditlogs, inclusief request- en responsegegevens, tijdstempels, gebruikte parameters, gebruikersinformatie en eventueel fouten. Dit maakt het mogelijk om achteraf te herleiden (en idealiter bevraagbaar) welke response destijds teruggegeven is.
- Elke wijziging in de data achter de API (en elke API-bevraging) kan worden vastgelegd als een event via Event Sourcing & Change Data Capture (CDC). Deze events vormen een onomstotelijke historie van alle wijzigingen (en bevragingen) en kunnen worden gebruikt om data op elk moment in het verleden te reconstrueren.
Combinatie (zoals inzage na gebeurtenis)
Binnen de Samenwerkfuncties zal nadrukkelijk ook een combinatie worden gebruikt. Een organisatie kan een notificatie doen (event uitsturen), andere organisaties kunnen op basis van het event een bevraging doen (REST API).
Deze werkwijze heeft als bijkomstig voordeel dat REST API authenticatie en autorisatie hergebruikt kan worden. Daardoor kan de complexiteit van het toegangslandschap worden gereduceerd.
Werking CORV2
De werking van CORV2 is in meer detail hieronder uitgebeeld en beschreven.
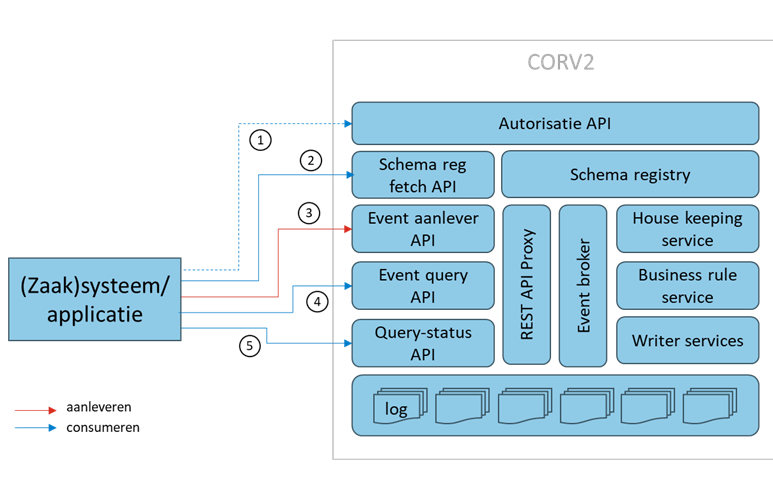
Stappen:
- Aanvragen van een autorisatie token voor event-log/topic (alleen voor gesloten topics)
- Opvragen van het schema
- Aanleveren van events (push)
- Opvraag events insturen (pull initiatie), response bevat request-id
- Opvragen event (pull) aan de hand van het request-id
CORV2 componenten:
- Schema registry – Opslag van event data schema’s t.b.v. versioning, backward/forward compatibility, validatie en voorkomen van breaking changes
- REST API (Proxy) – Transformatie van event streams naar REST API voor ontkoppeling en abstractie
- Event broker – Ontvangen, routeren en doorgeven van events
- House keeping service – Opschonen, retentie van event logs/topics
- Writer services – Database en Blockchain writers voor (immutable en onweerlegbare) opslag van events
Er wordt hiermee een asynchrone benadering gevolgd. Organisaties sturen events naar CORV2 (push), andere organisaties halen deze daar op (pull). De ‘pull’ vindt in twee stappen plaats (4 en 5 in de figuur). In de eerste stap geeft een organisatie aan in welke events deze organisatie interesse heeft. CORV geeft een request-id terug en gaat een query definiëren aan de hand van het verzoek. De organisatie vraagt met het request-id in een tweede stap of de events beschikbaar zijn. Als dat het geval is stuurt CORV2 het event of de events terug op basis van de query en het request-id. Deze benadering zorgt voor schaalbaarheid en performance.
CORV2 slaat events op om de asynchrone bevraging daarvan mogelijk te maken. Primair slaat CORV2 de events echter op om een ketenindex van gebeurtenissen mogelijk te maken. Daarmee kunnen bijvoorbeeld gebeurtenistijdslijnen zichtbaar worden gemaakt. Bij de opslag wordt gezorgd dat verbanden tussen events kunnen worden gelegd , de events onveranderlijk zijn (immutable/ append only) en onweerlegbaar, maar ook dat events vindbaar en te ‘queryen’ zijn. Hiervoor worden verschillende technologieën toegepast: provenance, block chain en graph.
Provenance:
W3C Provenance (PROV) is een standaard die beschrijft hoe je de herkomst, geschiedenis en afleiding van data kunt vastleggen en uitwisselen. Het draait om het modelleren van wie, wat, wanneer en hoe data is ontstaan of veranderd.
Provenance betekent letterlijk “herkomst”. In de context van data en W3C PROV gaat het om informatie over:
- Entiteiten: de data of objecten zelf.
- Activiteiten: processen of handelingen die data creëren, wijzigen of gebruiken.
- Agenten: personen, organisaties of systemen die verantwoordelijk zijn voor activiteiten.
Naast deze kernelementen kent PROV-DM (het PROV datamodel) relaties:
- wasGeneratedBy: een entity is voortgebracht door een activiteit.
- wasDerivedFrom: een entity is afgeleid van een andere.
- wasAttributedTo: een entity is toegeschreven aan een agent.
- used: een activiteit gebruikte een entity.
- wasAssociatedWith: een activiteit werd uitgevoerd door een agent.
De provenance-informatie helpt bij het beoordelen van de betrouwbaarheid, kwaliteit, verantwoordelijkheid en herleidbaarheid van data.
Provenance wordt gebruikt om events in PROV-DM formaat op te slaan en relaties (een ketting van events) te kunnen maken. Dit gaat om het command deel van CQRS (zie eerdere toelichting CQRS). Voor het query deel wordt graph toegepast (zie verderop).
Block chain:
Blockchain is een gedecentraliseerde digitale technologie waarmee gegevens veilig, transparant en onveranderlijk worden opgeslagen in blokken die met elkaar verbonden zijn in een keten. Hiermee wordt invulling gegeven aan de immutable-, append only- en onweerlegbaarheidsaspecten.
Graph:
Een graph database is een type database waar gegevens opgeslagen kunnen worden in de vorm van knooppunten (nodes) en relaties (edges), waardoor complexe verbanden tussen data efficiënt en intuïtief kunnen worden gemodelleerd en geanalyseerd. De graph wordt toegepast om events bevraagbaar te maken, of wel voor het query deel van CQRS.
Koppelvlakken
De asynchrone koppelvlakken van CORV2 zijn REST API koppelvlakken i.v.m. ontkoppeling en hergebruik van de authenticatie en autorisatie aanpak en voorzieningen bij REST API.
Events worden beschreven conform CloudEvents en meer specifiek het NL GOV profile for CloudEvents. De API’s worden beschreven conform AsyncAPI.
CloudEvents beschrijft de minimale, gestandaardiseerde event‑envelope: welke contextvelden (specversion, id, source, type, datacontenttype, dataschema, extensions) er zijn en hoe die seraliseert in binary of structured mode.
AsyncAPI is het OpenAPI‑achtige model voor asynchrone APIs: het beschrijft servers/brokers, channels (topics), berichten, operationele bindingen en payload‑schema’s; het dwingt de vorm van je API‑contract af en ondersteunt tooling, zoals documentatie en codegeneratie.
In onderstaande tabel is een vergelijk weergeven van CloudEvents en AsynAPI alsmede hoe beide in combinatie kunnen worden toegepast.
| Eigenschap | CloudEvents | AsyncAPI | Combinatie |
|---|---|---|---|
| Scope | Standaard voor event‑envelope / metadata | Specificatie voor volledige async API (channels, messages, servers) | Gebruik CloudEvents voor berichten; AsyncAPI voor documentatie van kanalen en contracten |
| Hoofddoel | Interoperabele event‑beschrijving | Ontwerp, documentatie en tooling voor messaging APIs | Documenteer CloudEvents‑gebaseerde events in AsyncAPI |
| Format / binding | Definieert contextvelden en serialisatie modes (binary/structured) | Beschrijft channels, bindings (Kafka, AMQP, HTTP) en berichtschema’s | Map CloudEvents velden naar bindings die AsyncAPI beschrijft |
| Schema en validatie | Verwijst naar dataschema (dataschema veld) maar specificeert geen payload‑DSL | Ondersteunt JSON Schema / Avro etc. voor payloads en genereert code/validators | Gebruik AsyncAPI om het payload‑schema (zoals JSON Schema) te hosten en te valideren |
| Tooling | Geen | Tooling voor docs, codegen, mock servers en contract testing | Gebruik AsyncAPI tooling voor docs en contracttests en optioneel voor Event Catalog / DevPortal |
Data-consistentie in de tijd
Er kunnen use cases zijn waarbij bevragingen bij de bron data-consistent in de tijd dienen te zijn. Van een oorspronkelijke bevraging dient na te gaan zijn wat de response destijds was. Vanuit logging of doordat de vraag opnieuw later in de tijd gedaan kan worden en dan gegarandeerd hetzelfde antwoord oplevert. Dit kan nodig zijn om bijvoorbeeld na te gaan op basis waarvan destijds beslissingen zijn genomen. Er zijn verschillende manieren om dit te realiseren, op bron niveau of door snapshots of logging.
Snapshots
Bij snapshots wordt een volledige kopie van de data op een bepaald moment gemaakt door de consumer van de databron. Dit levert reproduceerbaarheid op zonder afhankelijk te zijn van de bron, maar vergt ook veel opslag. Daarbij zij alleen snapshots voor bepaalde momenten beschikbaar en niet voor elke gewenste datum.
Logging
Zowel request als de response wordt opgeslagen (bij data consumer en/of data provider). Zo is exact terug te halen wat destijds is geleverd of ontvangen. Deze methode is vooral geschikt voor audit trails en compliance.
Bijhouden van historische versies bij de bron
De bron ondersteund meerdere versies van records, via bijvoorbeeld SCD (Slowly Changing Dimensions) en met een valid_from en valid_to datum. Waarbij een API een API kan een parameter “asOfDate” kan aanbieden. Consumers kunnen dan een bevraging doen voor een bepaalde state in time. Hier zorgt de bronhouder voor de historisatie en is de consumer daarvan afhankelijk.
Een probleem bij oplossingen die bevragingen in de tijd mogelijk maken bij de bron zijn wijzigingen in de API over tijd. Wanneer oude API versies niet meer beschikbaar zijn, kan de consistentie of het überhaupt kunnen bevragen van de API voor een gepaalde datum (met de originele vraag) in het gedrang komen. Als oude API versies beschikbaar gehouden worden zal dat doorgaans kostbaar zijn.
Binnen CORV2 worden gebeurtenissen in de tijd onweerlegbaar vast gelegd en is de reproduceerbaarheid en consistentie dus geborgd. Dit geldt niet automatisch voor API bevragingen tussen consumer en provider. Dat afhankelijk wat consumer en/of provider hiervoor hebben ingericht.
Toegang
Zowel bij gebeurtenissen als bij vraag- en antwoor- patronen kan informatie pas worden gezien of geraadpleegd als er daartoe toegang is. De ontvangende of vragende partij zal zich moeten authentiseren (bewijzen wie je bent) en moeten worden geautoriseerd (toegangsrechten ontvangen) voor toegang.
In voorliggende context gaat het vooral om toegangsverlening door de ene organisatie aan een andere organisatie. Binnen samenwerkingsverbanden/ketens wordt hierbij vrijwel altijd het concept van federatieve toegangsverlening toegepast. Federatieve toegangsverlening is een manier om op een veilige en gecontroleerde wijze toegang te regelen tot gegevens en systemen, waarbij meerdere organisaties samenwerken op basis van onderling vertrouwen.
Er zijn verschillende manieren van toegangsverlening in toegangsverlening tussen overheden:
- Organisatie identificatie(nummer) en certificaat
- Persoon + Organisatie en rol (RBAC)
- Persoon + Attributen/claims/policies (ABAC/CBAC/PBAC/ReBAC)
Bij toegangsverlening van bedrijven, intermediairs, eenmanszaken, stichtingen, etc. naar overheid of dienstaanbieders:
- eHerkenning - eHerkenning is een persoonsgebonden zakelijk inlogmiddel waarmee gebruikers namens hun organisatie veilig kunnen inloggen bij verschillende (overheids)diensten, zoals gemeenten, ministeries, verzekeraars en pensioenfondsen.
Bij toegangsverlening van burger naar overheid of dienstaanbieders
- eIDAS (DigiD – het Nederlandse nationale inlogmiddel dat is aangesloten op eIDAS)
- Self Sovereign Identity attributen
Binnen federatieve toegangsverlening speelt vertrouwen een rol. Denk aan vertrouwen in verordeningen als eIDAS en hun implementatie, vertrouwen in de sterkte van inlogmiddelen, vertrouwen in claims en attributen zoals deze door een organisatie worden aangeleverd etc.
OIN en certificaat
Een veel toegepaste toegangsverlening bij system2system gegevensuitwisseling is op basis van Organisatie identifier (Organisatie-Identificatienummer (OIN)) en (PKI-Overheid)certificaat. Dit is dan ook wat we in het stelsel in eerste instantie zullen gaan toepassen. Een organisatie krijgt toegang op basis van OIN en certificaat en er worden afspraken gemaakt wie toegang kan en mag krijgen. De aanvragende partij regelt deze toegang en de leverende partij vertrouwd op de gemaakte afspraken en implementatie daarvan. Tussen beide partijen wordt een beveiligd en versleuteld communicatie opgezet op basis van de OIN’s en certificaten. Wat betreft certificaten is het gebruik van PKIoverheid certificaten binnen het stelsel verplicht.
OIN en certificaat FSC-variant
FSC is een standaard die beschrijft hoe (overheids)organisaties op een gestandaardiseerde, veilige en schaalbare manier gegevens met elkaar kunnen uitwisselen zonder afhankelijk te zijn van een centrale partij. FSC werkt op eenzelfde manier als hiervoor beschreven bij OIN en certificaat, maar belooft schaalbaarheid, en bevat mogelijkheden om afspraken (contracten) gedigitaliseerd te kunnen maken. Verder is FSC een voorgeschreven standaard (zie Forum Standaardisatie). FSC is een betrekkelijk nieuwe standaard. Zo zijn er eind 2025 nog weinig tot geen productionele inter organisatie implementaties. De standaard wordt eind 2025 nog niet ondersteund door leveranciers. Wel is er een Open Source software implementatie beschikbaar (OpenFSC) waarmee organisaties kunnen testen. De verwachting is dat FSC-gebruik in de toekomst zal groeien. Binnen het stelsel willen we FSC dan ook gaan ondersteunen en afhankelijk van de ontwikkelingen daar mogelijk volledig op over gaan in de toekomst.
Persoon + Organisatie en rol
In plaats van organisatie kan ook toegang worden verleend op basis van persoon, organisatie en rol (RBAC). RBAC kan in de praktijk leiden tot een explosie van rollen. De toepassing van RBAC kan een tussenstap zijn naar Attributen/claims/policies gebaseerde toegang. RBAC kan worden gestapeld op OIN en certificaat gebaseerde toegang.
Een aantal rijksoverheid partijen, waaronder JenV, hebben een federatief stelsel waarin de verschillende gebruikersregistraties worden ontsloten via het SAML en OIDC/OAuth protocol. Personen in deze registraties kunnen op deze wijze geauthentiseerd worden. Personen kunnen inloggen met verschillende middelen en die middelen kunnen van verschillende sterkte zijn (denk aan password vs authenticator-app vs hardtoken). Er is dus ook verschil in betrouwbaarheidsniveau’s of wel Level of Assurance (LOA). Zie in dit kader bijvoorbeeld het JenV Trustframework.
Attributen/claims/policies
Een andere benadering rond toegangsverlening is toegangsverlening op basis van attributen/claims/policies. De toegang vragende partij levert attributen/claims, aan zoals wie het is die toegang wil, van welke organisatie deze persoon is, welke rol deze persoon heeft en aan welk dossier de toegangsaanvraag gelieerd is. De toegang verlenende partij beslist op basis van deze attributen/claims of de toegang verstrekt wordt. De toegang verlenende partij kan dat doen op basis van vooraf gedefinieerde policies. Dit type toegang is te stapelen op OIN en certificaat gebaseerde toegang. Binnen het stelsel willen we zoveel mogelijk naar deze manier van toegangsverlening bewegen. Ook hier geldt dat federatieve stelsels en bijbehorende gebruikersregistraties kunnen worden gebruikt voor de toegangsverlening (zie beschrijving bij Persoon + Organisatie en rol).
Attributen/claims/policies FTV-variant
Zoals FSC een variant is op het industriewijde Mutual TLS toegangsconcept (OIN/Certificaat benadering) en inmiddels een standaard, zo wordt er ook gewerkt aan de FTV-standaard als variant op het industriewijde ABAC/PBAC toegangsconcept en eveneens als standaard. FTV staat voor Federatieve Toegangsverlening. Het is een moderne standaard en methodiek om toegangsbeheer binnen het federatieve datastelsel (FDS) te organiseren. Aan FTV wordt eind 2025 nog gewerkt en de ontwikkeling zal tot in 2026 en mogelijk verder doorlopen. Ook FTV is te stapelen op FSC. De verwachting is dat FTV-gebruik in de toekomst zal groeien. Binnen het stelsel willen we FTV dan ook gaan ondersteunen en afhankelijk van de ontwikkelingen daar mogelijk volledig op over gaan in de toekomst.
FTV gebruikt AuthZEN als basisstandaard voor toegangsbeheer. AuthZEN is een open standaard binnen de OpenID Foundation die de interface standaardiseert tussen het Policy Enforcement Point (PEP) en het Policy Decision Point (PDP), wat essentieel is voor externalized authorization management. Het bevat een informatiemodel en API’s om toegangsbeslissingen real-time te maken op basis van wie toegang vraagt, wat wordt gevraagd, en in welke context dit plaatsvindt. FTV bouwt voort op AuthZEN voor het centraal beheren van toegangsregels en het maken van toegangsbeslissingen, waardoor toegang tot gegevens en diensten flexibel en veilig kan worden geregeld binnen federatieve omgevingen.
eHerkenning
eHerkenning is met name bedoeld voor toegang van bedrijven, intermediairs, eenmanszaken, stichtingen, etc. naar overheden en dienstaanbieders. Als hier binnen het stelsel sprake van is of gaat worden, dan zal eHerkenning voor deze toegangsverlening worden toegepast.
DigiD en eHerkenning ondersteunen de SAML standaard. Voor de toekomst is de verwachting dat DigiD/eHerkenning ook de OpenID Connect en OAuth-standaard zullen ondersteunen. Daar zullen we dan naar overstappen. Verder zal een (medewerker van) een bedrijf zich in de toekomst met een eWallet kunnen identificeren.
eIDAS /DigiD
eIDAS en DigiD zijn bedoeld voor digitale toegangsverlening, waarbij de gebruiker zich online identificeert en authentiseert om toegang te krijgen tot digitale diensten van de overheid en organisaties met een publieke taak. Als hier binnen het stelsel sprake van is of gaat worden, dan zal eIDAS /DigiD voor deze toegangsverlening worden toegepast.
DigiD en eHerkenning ondersteunen de SAML standaard. Voor de toekomst is de verwachting dat DigiD/eHerkenning ook de OpenID Connect en OAuth standaard zullen ondersteunen. Daar zullen we dan naar overstappen. Verder zal een burger zich in de toekomst met een Wallet kunnen identificeren, zie Self Sovereign Identitity.
Self Sovereign Identitity
Dit is een visie op identiteiten waarbij de gebruiker zelf centraal staat. De identiteit attributen zijn dan niet gebonden aan een specifieke partij of site. Ze zijn en blijven van de gebruiker en onder controle daarvan. De gebruiker kan de eigen identiteit voorzien van allerlei verklaringen die deels van henzelf komen (bijv. email adres) en deels van andere partijen. Gebruikers bepalen zelf aan wie ze de verklaringen en gegevens verstrekken en er worden geen gegevens verstrekt die niet nodig zijn.
Deze visie is terug te vinden in een aantal Wallets(apps).
Policy Based Access Control
Concept
Binnen het afsprakenstelsel wordt voor gegevensraadpleging gebruik gemaakt van authenticatie, autorisatie en in een federatief model policy based model. De kern van het PBAC- (en ReBAC) stelsel wordt beheerd door de Vertrouwensleverancier en maakt gebruik van open-source componenten, waaronder Open Policy Agent (OPA).
Het PBAC stelsel bestaat uit de volgende onderdelen:
- Policy Enforcement Point (PEP)
Voert het toegangsbesluit uit. Het controleert of een gebruiker toegang krijgt en handhaaft het besluit (toestaan of weigeren). - Policy Decision Point (PDP)
Neemt het toegangsbesluit. Het evalueert de beleidsregels op basis van de aanvraag en informatie van andere punten. - Policy Retrieval Point (PRP)
Slaat de beleidsregels op en levert ze aan de PDP wanneer die een besluit moet nemen. - Policy Administration Point (PAP)
Beheert en definieert de beleidsregels. Dit is de plek waar beheerders beleid aanmaken, wijzigen of verwijderen. - Policy Information Point (PIP)
Verzamelt extra contextuele informatie (zoals gebruikersattributen of omgevingsgegevens) die nodig is voor de PDP om een besluit te nemen.
Tevens uit:
- Autorisatieserver
Verantwoordelijk voor het uitgeven en beheren van toegangsrechten (zoals tokens). Ze controleert de identiteit van gebruikers en bepaalt op basis van beleid of en welke toegang wordt verleend. - Resource-server
Bevat de beschermde gegevens of diensten en verleent alleen toegang als de gebruiker een geldig toegangs- of autorisatietoken kan tonen, uitgegeven door de autorisatieserver.
De Audience (doelgroep of ontvanger) is de partij waarvoor het access token bedoeld is — meestal de resource-server.
Er zijn verschillende inrichtingen mogelijk, zoals volledige decentrale inrichting, een centrale inrichting en een hybride inrichting. Er worden beproevingen gedaan op dit vlak, voor nu wordt uitgegaan van een inrichting zoals hieronder beschreven. De kern daarvan is: decentrale uitvoering en beslissen, centrale kaders en vertrouwen.
Decentrale componenten bij de organisaties zelf:
- Vanzelfsprekend de Resource-server en PEP voor toepassen van de policies (verantwoordelijkheid) Bronhouder
- PDP, bij de resource-eigenaar voor autonome beslissingen; kan centrale regels inladen.
- PIP, lokale bronattributen blijven bij de organisatie; er kan sprake zijn van externe en centrale bronattributen.
- PAP, voor het definiëren van de lokale beleidsregels.
- Autorisatieserver, verifieert identiteiten en levert claims/tokens, maakt onderdeel uit van toegangsfederatie en kan verifiëren bij Identity Providers (IDP’s) van andere organisaties (via IDP-broker).
Gemeenschappelijk componenten welke organisaties zelf kunnen toepassen, maar elkaar daar wel voor nodig hebben:
- Toepassing van PKIoverheid voor de benodigde PKI-infrastructuur
- Toepassing FSC voor mutual TLS verbindingen op basis van contracten (potentieel gebruik van FDS FSC-directory en catalog)
Centrale componenten en centrale informatie-/beheertoegang gerelateerde afspraken (beide geleverd door de Vertrouwensleverancier):
- Afspraken t.a.v. PKIoverheid, FSC.
- Attribute-/claim-normalisatie mapping/normalisatie van attributen (schemas/entitlements) zodat claims van verschillende organisaties consistent zijn.
- PAP ketenvoorziening t.b.v. gezamenlijke normen, -taxonomie (namen van attributen/rollen) en “baseline policies”.
- PRP ketenvoorziening, t.b.v. verspreiding van centrale/baseline policies en gemeenschappelijke modules.
- Federation broker, voor token brokering (audience scoping, token exchange).
Deze inrichting levert op:
- Autonomie & performance: handhaving (PEP) en beslissen (PDP) dicht bij de resource.
- Consistentie & vertrouwen: policy-kaders, attributenschema en sleutels centraal.
- Privacy by design: attributen blijven waar ze ontstaan; alleen noodzakelijke, genormaliseerde claims delen.
- Schaalbaarheid: elke organisatie beheert eigen policies/identiteiten, terwijl de federatie het “spelregelboek” en de trust laag levert.
Datakwaliteit
Merk op dat PBAC alleen goed kan werken als de datakwaliteit, datamodel en de semantiek op orde zijn. Anders wordt het immers moeilijk om policies te definiëren die een consistente uitkomst kennen.
Autoriseren
Voor het uitvoeren van activiteiten zijn autorisaties noodzakelijk. Voorbeelden van activiteiten zijn: lezen, schrijven, aanpassen en verwijderen van data.
Schematische weergave aanvragen van autorisatie (REST/GraphQL voorbeeld):
| # | Processtap | Beschrijving |
|---|---|---|
| 1 | Aanvragen van autorisatie | De Client vraagt autorisatie aan bij het token endpoint van de autorisatieserver. |
| 2 | Valideer authenticatiemiddel | De autorisatieserver valideert de client op basis van het aangeboden authenticatiemiddel (bijv. certificaat). |
| 3 | Beoordeel scope | De autorisatieserver doorloopt voor elke aanvraag de rule-engine om de aangevraagde scopes te beoordelen. |
| 4 | Controleer audience | De rule-engine valideert de aangevraagde scopes op basis van ingestelde beleidsregels. |
| 5 | Genereer en retourneer | Als de aanvraag succesvol is, wordt een access-token gegenereerd met de goedgekeurde scopes en resources. |
| 6 | Foutmeldingen | Fouten in de aanvraag of van de server worden geretourneerd. |
Autorisatieserver: Bij een autorisatieserver kunnen deelnemers toestemming tot autorisatie aanvragen. De autorisatieaanvraag voldoet aan de OAuth 2.0 standaard. Het resultaat van de aanvraag is een access-token (JWT). Toegang tot deze autorisatieserver is beperkt tot alleen deelnemers en alleen via het token-endpoint waarvoor een vertrouwd authenticatiemiddel vereist is. Momenteel alleen met gebruik van een PKIoverheid-systeemcertificaat.
Client Credential Flow: OAuth 2.0 ondersteunt verschillende “flow standaarden” (ook wel grants genoemd) om toegang te verlenen. Voor server-naar-server communicatie wordt meestal de “Client Credential Flow” toegepast. Deze “Client Credential flow” wordt ook gebruikt bij het aanvragen van toestemming tot autorisatie bij de autorisatieserver.
Scope: Een (OAuth) scope geeft het bereik van autorisatie tot een resource aan. Een scope kan een deelnemer bij de autorisatieserver aanvragen. Systemen gebruiken een OAuth scope om na te gaan welke acties een client mag doen. De autorisatieserver vereist dat de client in het autorisatieverzoek een scope parameter specificeert. De scope geeft het bereik aan waarvoor autorisatie wordt aangevraagd en daarmee beperkt en specificeert de scope welke gegevens of functionaliteiten de client kan bevragen of gebruiken. Een scope is opgebouwd uit de combinatie van resource-type en de benodigde toegang.
Audience:
- Als je in OAuth een Access-token aanvraagt, moet je specificeren wie of wat de uiteindelijke ontvanger van deze token is, deze ontvanger wordt aangeduid als Audience. Dit helpt om te verzekeren dat het token alleen kan worden gebruikt bij de bedoelde resource-server en nergens anders.
- Het opgeven van een Audience is verplicht.
- Er is één Audience toegestaan.
- De audience moet een valide “https” URL zijn. De Audience is de afgeschermde URL van de resource-server welke ook alleen de Policy Enforcement Point van de resource-server vertrouwd.
Access-token request: Een Access-token request is een toegangsverzoek om toegang te krijgen tot een resource-server. In een Access-token request wordt aangegeven namens wie het request wordt uitgevoerd. Dit kan op twee manieren, als de partij zelf of als actor namens een partij. In beide gevallen wordt een request gedaan met een PKIoverheid systeemcertificaat (authenticatiemiddel) om te bepalen wie de partij is. Om toegang te krijgen, moet in het tokenaanvraagproces naast het systeemcertificaat ook worden aangegeven namens welke partij de actor handelt (naam of code). De actor fungeert als vertegenwoordiger van de instantie en zorgt ervoor dat toegangsverzoeken correct en veilig worden geautoriseerd, zodat altijd duidelijk is namens welke partij de aanvraag wordt uitgevoerd. Wanneer als actor een request wordt ingediend, moet het token worden uitgebreid met een “access-token/sub” element. Dit element bevat de identificatie van de partij waarvoor een token wordt opgehaald.
Toegangsverlening
Autorisaties worden aangevraagd om toegang te verkrijgen tot gegevens. De gegevens worden beschikbaar gesteld door een Resource Server en dat alleen wanneer een verzoek succesvol is gevalideerd door de voorafgaande beveiligings- en autorisatieprocessen.
Een Resource Server beheert en verstrekt gegevens op basis van goedgekeurde toegangsverzoeken. Elk verzoek moet daarbij worden gevalideerd op basis van een Access-token, scope en beleidsregels via het Policy Enforcement Point (PEP). Dat volgens het least privilege-principe, waarbij deelnemers alleen toegang krijgen tot de gegevens die strikt noodzakelijk zijn. Er moeten limieten worden ingesteld op het aantal toegangsverzoeken (rate limiting) om misbruik te voorkomen. Het Policy Enforcement Point (PEP) moet verzoeken naar het juiste datatoegangspunt routeren, afhankelijk van de gevraagde gegevens en beleidsregels.
Schematische weergave interactie met een Resource Server (REST/GraphQL voorbeeld):
| # | Processtap | Beschrijving |
|---|---|---|
| 1 | Query + Acces-token | De deelnemer dient een query in bij de PEP, samen met een geldig access-token. |
| 2 | Doorsturen geautoriseerd verzoek | De PEP valideert de query en besluit of deze naar het juiste Resource Server wordt doorgestuurd. |
| 3 | Gevraagde data | De Resource Server verwerkt de query en retourneert de gevraagde gegevens aan de PEP. |
| 4 | Gevraagde data | De PEP routeert het resultaat aan de client. De PEP heeft hierbij geen toegang tot de gerouteerde data en dus geen mogelijkheid tot bewerking of inzicht van de data. |
PEP
Het Policy Enforcement Point (PEP) regelt toegang tot resource-servers van deelnemers en beschermt deze resource-servers tegen ongeautoriseerde toegang/verzoeken. Een deelnemer (client) kan met behulp van een access-token een verzoek doen bij de Policy Enforcement Point (PEP). De PEP valideert het verzoek (query), past beleidsregels toe en stuurt het verzoek door naar de juiste Resource Server.
Schematische weergave interactie met de PEP (REST/GraphQL voorbeeld):
| # | Processtap | Beschrijving |
|---|---|---|
| 1 | REST/GraphQL Request | Een client kan met het access-token een verzoek uitzetten bij de PEP om een raadpleging te doen bij een Resource Server. |
| 2 | Valideer Authenticatiemiddel | Valideren van de client o.b.v. het aangeboden authenticatiemiddel. |
| 3 | Valideer Access-token | Valideren van de access-token o.a. op eigenaar en geldigheid. |
| 4 | Query met policy valideren | De query wordt aangeboden aan het PDP om te beoordelen of deelnemer de ingediende query mag uitvoeren en of de verplichte onderdelen aanwezig zijn. |
| 5 | Valideer query | Bepaal of de query aan de gestelde policy of beleidsregel voldoet. |
| 6 | Verify context information | Het kan nodig zijn dat het PDP contextinformatie nodig heeft om de query te valideren. Dit kan het PDP doen bij een externe resource. |
| 7 | Query allowed | Query voldoet aan de policy. |
| 8 | REST/GraphQL Request | De PEP routeert het verzoek aan de juiste Resource Server. |
| 9 | 200 Response (REST/GraphQL) | De Resource Server stuurt het resultaat terug. |
| 10 | 200 Response (REST/GraphQL) | De PEP routeert het resultaat aan de client. De PEP heeft hierbij geen toegang tot de gerouteerde data en dus geen mogelijkheid tot bewerking of inzicht van de data. |
PDP
Het PDP is verantwoordelijk voor het nemen van toegangsbeslissingen op basis van beleidsregels (policies) en analyseert toegangsverzoeken die worden ingediend.
Schematische weergave interactie met de PDP (REST/GraphQL voorbeeld):
| # | Processtap | Beschrijving |
|---|---|---|
| 1 | Query + access token | Het Policy Enforcement Point (PEP) stuurt een toegangsverzoek in de vorm van een query naar het Policy Decision Point (PDP). Dit bestaat uit een query en access-token. |
| 2 | Ophalen beleidsregels | Het PDP stuurt een verzoek naar het Policy Retrieval Point (PRP) om de relevante beleidsregels op te halen. Deze beleidsregels worden gebruikt om te bepalen of de aangevraagde acties en entiteiten in de query zijn toegestaan. |
| 3 | Beleidsregels retourneren | Het PRP retourneert de beleidsregels aan het PDP. Deze beleidsregels bevatten de toegangscriteria die het PDP gebruikt om het verzoek te evalueren. |
| 4 | Besluit toestaan/weigeren | Het PDP evalueert het toegangsverzoek aan de hand van de ontvangen beleidsregels. Er wordt een besluit genomen:Allow: Toegang wordt verleend.Deny: Toegang wordt geweigerd. |
| 5 | Besluit vastleggen | Het PDP legt elk genomen besluit vast in een Decision Log.Het log bevat zaken zoals: details van de ingediende query, de gebruikte beleidsregels en het uiteindelijke toegangsbesluit (Allow of Deny). |
PRP
Het Policy Retrieval Point (PRP) zorgt voor het beheer en de levering van beleidsregels (policies) binnen het Afsprakenstelsel. Als centrale opslagplaats zorgt het PRP ervoor dat beleidsregels consistent worden opgeslagen, beheerd en toegankelijk zijn voor andere onderdelen, zoals het Policy Decision Point (PDP). Deze centrale aanpak waarborgt dat alle toegangsbeslissingen gebaseerd zijn op dezelfde regels, waardoor consistentie in toegangscontrole wordt gegarandeerd.
Daarnaast biedt het PRP transparantie door gebruik te maken van een versiebeheersysteem, zoals GitHub, waarmee alle wijzigingen in beleidsregels inzichtelijk en traceerbaar zijn. Dit maakt het eenvoudig om beleidsregels te beheren, bij te werken en wijzigingen consistent door te voeren in het hele netwerk, wat de beheerbaarheid aanzienlijk vergroot.
Schematische weergave interactie met de PRP (voorbeeld):
| # | Processtap | Beschrijving |
|---|---|---|
| 1 | Toegangsverzoek | Het proces begint wanneer een toegangsverzoek wordt ingediend door een deelnemer (Client). Dit verzoek wordt door het Policy Enforcement Point (PEP) doorgestuurd naar het Policy Decision Point (PDP). Het bevat alle benodigde informatie, zoals een query, een access-token, en de gevraagde acties en scopes. |
| 2 | Valideren verzoek | Het PDP valideert het toegangsverzoek op basis van de ontvangen informatie. Dit omvat de controle op de geldigheid van het access-token en de aanwezigheid van de juiste scopes. Tijdens deze validatie kan het PDP vaststellen dat aanvullende beleidsregels nodig zijn om een besluit te kunnen nemen. |
| 3 | Ophalen beleidsregels | Indien aanvullende regels nodig zijn, stuurt het PDP een verzoek naar het PRP om de relevante beleidsregels op te halen. Het PRP zoekt in zijn centrale opslag naar de regels die van toepassing zijn op de ingediende query en retourneert deze naar het PDP. Deze stap is cruciaal om ervoor te zorgen dat het toegangsbesluit wordt gebaseerd op actuele en gedefinieerde beleidsregels. |
| 4 | Besluit: toegang of weigeren | Met de opgehaalde beleidsregels en de eerder ontvangen informatie neemt het PDP een besluit. Dit besluit bepaalt of het toegangsverzoek wordt toegestaan of geweigerd. Het PDP gebruikt hierbij de beleidsregels om te controleren of de gevraagde acties voldoen aan de toegangscriteria. |
| 5 | Resultaat terugsturen | Het PDP stuurt het besluit terug naar het PEP, dat dit vervolgens communiceert naar de deelnemer (Client). Bij een positief besluit kan de client toegang krijgen tot de gevraagde resource, terwijl bij een negatief besluit het verzoek wordt geweigerd. |
PAP
Via het Policy Administration Point (PAP) worden beleidsregels (policies) beheerd. Het PAP zorgt ervoor dat deze regels consistent beschikbaar zijn voor andere componenten zoals het Policy Retrieval Point (PRP) en het Policy Decision Point (PDP).
Schematische weergave interactie met de PAP (voorbeeld):
| # | Processtap | Beschrijving |
|---|---|---|
| 1 | Creëren of aanpassen van beleidsregels | Beheerders maken nieuwe beleidsregels aan of wijzigen bestaande regels via de interface van het PAP. |
| 2 | Validatie van beleidsregels | Het PAP valideert de beleidsregels op correctheid, consistentie en afstemming met bestaande regels. |
| 3 | Versiebeheer | Het PAP slaat beleidsregels op in een versiebeheersysteem, zodat wijzigingen historisch worden vastgelegd. |
| 4 | Publicatie van beleidsregels | De gevalideerde beleidsregels worden gepubliceerd naar het PRP voor distributie naar andere componenten. |
| 5 | Synchronisatie met het PDP | Het PAP synchroniseert de beleidsregels met het PDP, zodat deze de meest recente regels gebruikt. |
PIP
Het PIP levert contextuele informatie die nodig is voor het evalueren van toegangsverzoeken. Deze informatie kan afkomstig zijn uit externe bronnen of interne gegevensbronnen.
Schematische weergave interactie met de PAP (voorbeeld):
| # | Processtap | Beschrijving |
|---|---|---|
| 1 | Toegangsverzoek | Het Policy Enforcement Point (PEP) stuurt een toegangsverzoek naar het Policy Decision Point (PDP). Dit verzoek bevat informatie zoals de benodigde scopes en de authenticatie van de gebruiker. |
| 2 | Behoefte aan aanvullende informatie | Tijdens de evaluatie van het toegangsverzoek merkt het PDP dat aanvullende contextinformatie nodig is om de beleidsregels correct te kunnen evalueren. |
| 3 | Contextinformatie opvragen | Het PDP stuurt een verzoek naar het Policy Information Point (PIP) om aanvullende gegevens op te halen. Dit kan bijvoorbeeld informatie zijn over de rol van een deelnemer of specifieke attributen die nodig zijn voor de beoordeling.Het PIP kan een breed scala aan contextinformatie verstrekken, zoals:IdentiteitsinformatieRol of status van de deelnemer (bijvoorbeeld zorgverlener of patiënt).Relatie-informatieVerbanden tussen entiteiten, zoals een zorgverlener die toegang vraagt tot gegevens van een specifieke patiënt.TijdrestrictiesControle of toegang binnen de toegestane tijdsperiode valt.BeveiligingsregelsVerificatie van compliance met beveiligingsstandaarden. |
| 4 | Gegevens ophalen | Het PIP raadpleegt een relevante bron, zoals een interne database of een externe bron, om de gevraagde contextinformatie op te halen. |
| 5 | Gegevens retourneren | De opgehaalde gegevens worden teruggestuurd van de bron naar het PIP, zodat deze beschikbaar zijn voor verdere verwerking. |
| 6 | Informatie terugkoppelen | Het PIP retourneert de verzamelde contextinformatie naar het PDP, zodat deze gebruikt kan worden voor het maken van een toegangsbesluit. |
| 7 | Besluit toestaan/weigeren | Het PDP gebruikt de verstrekte informatie en de beleidsregels om een besluit te nemen over het toegangsverzoek. Dit besluit wordt teruggestuurd naar het PEP, dat het uiteindelijke resultaat communiceert naar de client. |